我们该如何运用Python 来统计字数呢
小编经常看到有用户吐槽用Python 来对字数进行统计太麻烦了,感觉很鸡肋,用处不大。其实只要你找对操作方法,你会发现Python用起来太方便了。下面将给大家介绍使用Python来解决字数统计的详细步骤,希望能给大家提供到帮助。
问题描述:
用 Python 实现函数 count_words(),该函数输入字符串 s 和数字 n,返回 s 中 n 个出现频率最高的单词。返回值是一个元组列表,包含出现次数最高的 n 个单词及其次数,即 [(<单词1>, <次数1>), (<单词2>, <次数2>), ... ],按出现次数降序排列。
您可以假设所有输入都是小写形式,并且不含标点符号或其他字符(只包含字母和单个空格)。如果出现次数相同,则按字母顺序排列。
例如:
输出:
[('butter', 2), ('a', 1), ('betty', 1)]
解决问题的思路:
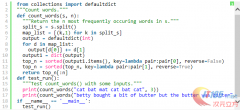
1. 将字符串s进行空白符分割得到所有的单词列表split_s,如:['betty', 'bought', 'a', 'bit', 'of', 'butter', 'but', 'the', 'butter', 'was', 'bitter']
2. 建立maplist,将split_s转化为元素为元组的列表形式,如:[('betty', 1), ('bought', 1), ('a', 1), ('bit', 1), ('of', 1), ('butter', 1), ('but', 1), ('the', 1), ('butter', 1), ('was', 1), ('bitter', 1)]
3. 合并maplist中元素,元组的第一个索引值相同,则将其第二个索引值相加。
// 备注:准备采用defaultdict。得到的数据如下:{'betty': 1, 'bought': 1, 'a': 1, 'bit': 1, 'of': 1, 'butter': 2, 'but': 1, 'the': 1, 'was': 1, 'bitter': 1}
4. 进行排序,按照key进行字母排序,得到如下:[('a', 1), ('betty', 1), ('bit', 1), ('bitter', 1), ('bought', 1), ('but', 1), ('butter', 2), ('of', 1), ('the', 1), ('was', 1)]
5. 进行二次排序, 按照value进行排序,得到如下:[('butter', 2), ('a', 1), ('betty', 1), ('bit', 1), ('bitter', 1), ('bought', 1), ('but', 1), ('of', 1), ('the', 1), ('was', 1)]
6. 使用切片取出频率较高的*组数据
总结:在python3上不进行defaultdict进行排序结果也是正确的,python2上不正确。defaultdict本身是没有顺序的,要区分列表,所以必须进行排序。
也可尝试自己写,不借助第三方模块
解决方案1(使用defaultdict):

解决方案2(使用Counter)

上文对Python在统计字数方面的运用都有很完整的介绍,而且还另外介绍了如何不使用第三方模块来处理的办法,大家可以任意选择适合自己使用的方法,总有一款是适合你的。大家不要总是感觉很难不敢去尝试,其实你尝试了之后会觉得原来自己都是多虑了。
相关热词:
本站内容来源于网络,如有侵权请与我们联系,我们会及时删除,我们深感抱歉!
注:本站所有信息仅供用于网络技术学习参考,学习中请遵循相关法律法规!
本文地址: https://v30.fanwenzhu.com/jiaob/python/9691.shtml
相关文章
热门TAG
win10 ecshop 主机 阿里云 解决 配置 C# C++ 解析 SQL语句 命令 Go语言 方法 CSS3 HTML5 CSS win7 MSSQL 服务器配置 IIS7.5 IIS7 IIS6 IIS CentOS 7 Linux oracle数据库 oracle phpcms discuz discuz教程最新文章
-
 python日常一 利用python抓取
python日常一 利用python抓取
时间:2021-01-17
-
 一个 ARP 请求分组询问协议
一个 ARP 请求分组询问协议
时间:2021-01-17
-
 此时就需要web抓取
此时就需要web抓取
时间:2021-01-17
-
 这节我们使用Bootstrap
这节我们使用Bootstrap
时间:2021-01-17
-
 我们该如何运用Python 来统
我们该如何运用Python 来统
时间:2020-12-27
-
 python生成汉字图片字库
python生成汉字图片字库
时间:2020-12-26
-
 python通过protobuf实现rpc
python通过protobuf实现rpc
时间:2020-12-26
-
 djngo快速实现使用Bootstra
djngo快速实现使用Bootstra
时间:2020-12-26
热门文章
-
 python中制表符是什么意思
python中制表符是什么意思
时间:2020-12-19
-
 python利用format方法保留三位小数
python利用format方法保留三位小数
时间:2020-12-19
-
 python的for循环怎么理解
python的for循环怎么理解
时间:2020-12-19
-
 python根据年份月份输出天数
python根据年份月份输出天数
时间:2020-12-19
-
 python日常一 使用python抓取拉勾网职位信息
python日常一 使用python抓取拉勾网职位信息
时间:2020-12-26
-
 python实现计算列表元素之和
python实现计算列表元素之和
时间:2020-12-19
-
 python输出结果怎么换行
python输出结果怎么换行
时间:2020-12-20
-
 python实现字符串逆序输出
python实现字符串逆序输出
时间:2020-12-20
-
 winpython是什么
winpython是什么
时间:2020-12-20
-
 python中swapcase是什么意思
python中swapcase是什么意思
时间:2020-12-20